北京北大青鸟学术部提供:
假设你想找到本书中的某一个句子。你可以一页一页地逐页搜索,但这会花很时间。而通过使用本书的索引,你可以很快地找到你要搜索的主题。表的索引与附在一本书后面的索引非常相似。它可以极大地提高查询的速度。对一个较大的表来说,通过加索引,一个通常要花费几个小时来完成的查询只要几分钟就可以完成。
因此没有理由对需要频繁查询的表增加索引。
注意:
当你的内存容量或硬盘空间不足时,也许你不想给一个表增加索引。对于包含索引的数据库,SQL Sever 需要一个可观的额外空间。例如,要建立一个聚簇索引,需要大约1.2倍于数据大小的空间。要看一看一个表的索引在数据库中所占的空间大小,你可以使用系统存储过程sp_spaceused,对象名指定为被索引的表名。
聚簇索引和非聚簇索引(北京北大青鸟)
假设你已经通过本书的索引找到了一个句子所在的页码。一旦已经知道了页码后,你很可能漫无目的翻寻这本书,直至找到正确的页码。通过随机的翻寻,你最终可以到达正确的页码。但是,有一种找到页码的更有效的方法。
首先,把书翻到大概一半的地方,如果要找的页码比半本书处的页码小,就书翻到四分之一处,否则,就把书翻到四分之三的地方。通过这种方法,你可以继续把书分成更小的部分,直至找到正确的页码附近。这是找到书页的非常有效的一种方法。
SQL Sever 的表索引以类似的方式工作。一个表索引由一组页组成,这些页构成了一个树形结构。根页通过指向另外两个页,把一个表的记录从逻辑上分成和两个部分。而根页所指向的两个页又分别把记录分割成更小的部分。每个页都把记录分成更小的分割,直至到达叶级页。
索引有两种类型:聚簇索引和非聚簇索引。在聚簇索引中,索引树的叶级页包含实际的数据:记录的索引顺序与物理顺序相同。在非聚簇索引中,叶级页指向表中的记录:记录的物理顺序与逻辑顺序没有必然的联系。
聚簇索引非常象目录表,目录表的顺序与实际的页码顺序是一致的。非聚簇索引则更象书的标准索引表,索引表中的顺序通常与实际的页码顺序是不一致的。一本书也许有多个索引。例如,它也许同时有主题索引和作者索引。同样,一个表可以有多个非聚簇索引。通常情况下,你使用的是聚簇索引,但是你应该对两种类型索引的优缺点都有所理解。每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。通常你要对一个表按照标识字段建立聚簇索引。但是,你也可以对其它类型的字段建立聚簇索引,如字符型,数值型和日期时间型字段。从建立了聚簇索引的表中取出数据要比建立了非聚簇索引的表快。当你需要取出一定范围内的数据时,用聚簇索引也比用非聚簇索引好。例如,假设你用一个表来记录访问者在你网点上的活动。如果你想取出在一定时间段内的登录信息,你应该对这个表的DATETIME 型字段建立聚簇索引。
对聚簇索引的主要限制是每个表只能建立一个聚簇索引。但是,一个表可以有不止一个非聚簇索引。实际上,对每个表你最多可以建立249个非聚簇索引。你也可以对一个表同时建立聚簇索引和非聚簇索引。(北京北大青鸟)
假如你不仅想根据日期,而且想根据用户名从你的网点活动日志中取数据。在这种情况下,同时建立一个聚簇索引和非聚簇索引是有效的。你可以对日期时间字段建立聚簇索引,对用户名字段建立非聚簇索引。如果你发现你需要更多的索引方式,你可以增加更多的非聚簇索引。
非聚簇索引需要大量的硬盘空间和内存。另外,虽然非聚簇索引可以提高从表中 取数据的速度,它也会降低向表中插入和更新数据的速度。每当你改变了一个建立了非聚簇索引的表中的数据时,必须同时更新索引。因此你对一个表建立非聚簇索引时要慎重考虑。如果你预计一个表需要频繁地更新数据,那么不要对它建立太多非聚簇索引。另外,如果硬盘和内存空间有限,也应该限制使用非聚簇索引的数量。
索引属性
这两种类型的索引都有两个重要属性:你可以用两者中任一种类型同时对多个字段建立索引(复合索引);两种类型的索引都可以指定为唯一索引。
你可以对多个字段建立一个复合索引,甚至是复合的聚簇索引。假如有一个表记录了你的网点访问者的姓和名字。如果你希望根据完整姓名从表中取数据,你需要建立一个同时对姓字段和名字字段进行的索引。这和分别对两个字段建立单独的索引是不同的。当你希望同时对不止一个字段进行查询时,你应该建立一个对多个字段的索引。如果你希望对各个字段进行分别查询,你应该对各字段建立独立的索引。(北京北大青鸟)
两种类型的索引都可以被指定为唯一索引。如果对一个字段建立了唯一索引,你将不能向这个字段输入重复的值。一个标识字段会自动成为唯一值字段,但你也可以对其它类型的
字段建立唯一索引。假设你用一个表来保存你的网点的用户密码,你当然不希望两个用户有相同的密码。通过强制一个字段成为唯一值字段,你可以防止这种情况的发生。
用SQL建立索引
为了给一个表建立索引,启动任务栏SQL Sever 程序组中的ISQL/w 程序。进入查询窗
口后,输入下面的语句:
CREATE INDEX mycolumn_index ON mytable (myclumn)
这个语句建立了一个名为mycolumn_index 的索引。你可以给一个索引起任何名字,但你应该在索引名中包含所索引的字段名,这对你将来弄清楚建立该索引的意图是有帮助的。
注意:
在本书中你执行任何SQL语句,都会收到如下的信息:
This command did not return data,and it did not return any rows
这说明该语句执行成功了。
索引mycolumn_index对表mytable 的mycolumn字段进行。这是个非聚簇索引,也是个非唯一索引。(这是一个索引的缺省属性)如果你需要改变一个索引的类型,你必须删除原来的索引并重建 一个。建立了一个索
引后,你可以用下面的SQL 语句删除它:
DROP INDEX mytable.mycolumn_index
注意在DROP INDEX 语句中你要包含表的名字。在这个例子中,你删除的索引是
mycolumn_index,它是表mytable 的索引。
要建立一个聚簇索引,可以使用关键字CLUSTERED。)记住一个表只能有一个聚簇索引。
(这里有一个如何对一个表建立聚簇索引的例子:(北京北大青鸟)
CREATE CLUSTERED INDEX mycolumn_clust_index ON mytable(mycolumn)
如果表中有重复的记录,当你试图用这个语句建立索引时,会出现错误。但是有重复记录的表也可以建立索引;你只要使用关键字ALLOW_DUP_ROW把这一点告诉SQL Sever 即可:
CREATE CLUSTERED INDEX mycolumn_cindex ON mytable(mycolumn)
WITH ALLOW_DUP_ROW
这个语句建立了一个允许重复记录的聚簇索引。你应该尽量避免在一个表中出现重复记录,但是,如果已经出现了,你可以使用这种方法。
要对一个表建立唯一索引,可以使用关键字UNIQUE。对聚簇索引和非聚簇索引都可以使用这个关键字。这里有一个例子:
CREATE UNIQUE COUSTERED INDEX myclumn_cindex ON mytable(mycolumn)
这是你将经常使用的索引建立语句。无论何时,只要可以,你应该尽量对一个对一个表建立唯一聚簇索引来增强查询操作。最后,要建立一个对多个字段的索引──复合索引──在索引建立语句中同时包含多个字段名。下面的例子对firstname 和lastname两个字段建立索引:
CREATE INDEX name_index ON username(firstname,lastname)
这个例子对两个字段建立了单个索引。在一个复合索引中,你最多可以对16 个字段进
行索引。
一. 聚集索引B树分析(北京北大青鸟)
1.聚集索引按B树结构进行组织的,索引B树种的每一页称为一个索引节点。B树的顶端节点称为根节点。
索引中的低层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。
根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行.每级索引中的页均被连接在双向链接列表中。
2.索引使用的每一个分区的index_id = 1 ,默认情况下聚集索引单个分区,当使用分区表的时候,每个分区都有一个包含该特定分区相关数据的B树结构,我是这么理解的不知道对不对?
3.SQL Server 写入的数据,数据链内的页和行将按聚集索引键值进行排序。
4.SQL Server 将在索引中查找该范围的起始键值,然后用向前或向后在数据页中进行扫描。为了查找数据页链的首页,SQL Server 将从索引的根节点沿最左边的指针进行扫描。
聚集索引B树图 :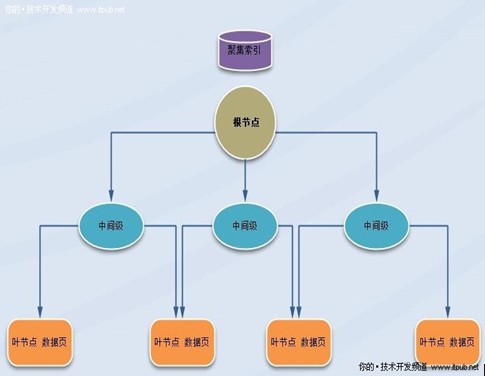
二 .优化 Transact-SQL 语句经常使用的语句 (北京北大青鸟)
1.SET STATISTICS IO {ON| OFF} /*Transact-SQL 语句生成的磁盘活动量的信息*/
2.SET SHOWPLAN_ALL ON {ON| OFF} /*返回有关语句执行情况的详细信息,并估计语句对资源的需求*/
3.SET STATISTICS TIME {ON| OFF} /*显示分析、编译和执行各语句所需的毫秒数*/
4.使用T-SQL语句创建索引的语法:
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name)
[WITH FILLFACTOR=x]
一. 聚集索引B树分析
1.聚集索引按B树结构进行组织的,索引B树种的每一页称为一个索引节点。B树的顶端节点称为根节点。
索引中的低层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。
根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行.每级索引中的页均被连接在双向链接列表中。
2.索引使用的每一个分区的index_id = 1 ,默认情况下聚集索引单个分区,当使用分区表的时候,每个分区都有一个包含该特定分区相关数据的B树结构,我是这么理解的不知道对不对?
3.SQL Server 写入的数据,数据链内的页和行将按聚集索引键值进行排序。
4.SQL Server 将在索引中查找该范围的起始键值,然后用向前或向后在数据页中进行扫描。为了查找数据页链的首页,SQL Server 将从索引的根节点沿最左边的指针进行扫描。(北京北大青鸟)
聚集索引B树图 :
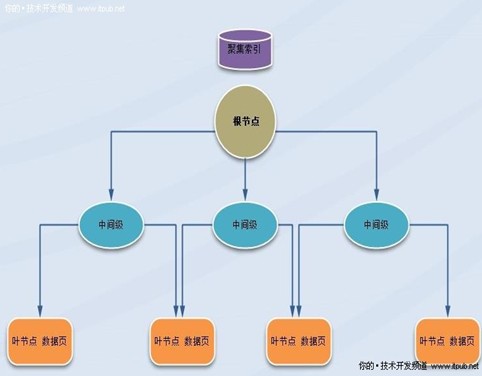
二 .优化 Transact-SQL 语句经常使用的语句
1.SET STATISTICS IO {ON| OFF} /*Transact-SQL 语句生成的磁盘活动量的信息*/
2.SET SHOWPLAN_ALL ON {ON| OFF} /*返回有关语句执行情况的详细信息,并估计语句对资源的需求*/
3.SET STATISTICS TIME {ON| OFF} /*显示分析、编译和执行各语句所需的毫秒数*/
4.使用T-SQL语句创建索引的语法:
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name)
[WITH FILLFACTOR=x]
三 创建数据测试下上面学到的理论知识(北京北大青鸟)
--创建表
CREATE TABLE employee
(
emp_username varchar (20),
emp_register DATETIME
)
--插入测试数据
DECLARE @startid INT
DECLARE @endid INT
SELECT @startid= 1,@endid = 100
WHILE @startid <=@endid
BEGIN
INSERT INTO employee (
emp_username,
emp_register
) VALUES (
/* emp_username - varchar (20) */ '刘'+CAST(@startid AS NVARCHAR(20)),
/* emp_register - DATETIME */ GETDATE() )
SELECT @startid =@startid +1;
END
-- 查询employee的执行计划 和 io 信息
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '刘'
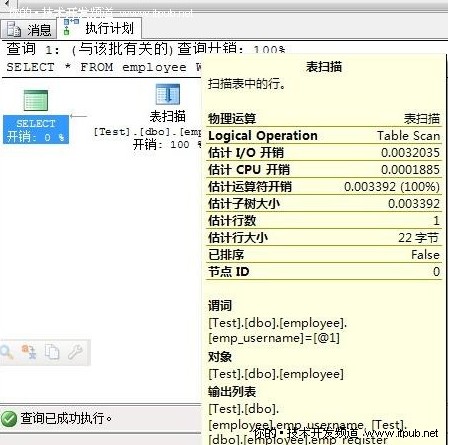
查看消息输出的 IO 信息
表'employee'。(1)1扫描计数1,(2)逻辑读取1 次,(3)物理读取0 次,(4)预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
输出的信息和上面的图片讲解的是对应的
1. 执行的扫描次数 。
2. 从磁盘读取的页数。
3. 为进行查询而放入缓存的页数。
4. 预读
T_SQL transaction 语句有很多种的写法,但是决定那条语句是最优的是根据(logical reads) 逻辑读取来判断。(北京北大青鸟)
添加聚集索引 查询逻辑读取是否会变少
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
--然后再执行查询
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '刘'
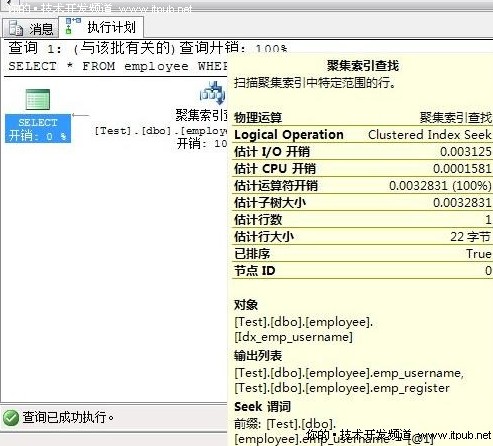
查看消息输出的 IO 信息
表'employee'。扫描计数1,逻辑读取2 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
Q 这次逻辑读取是2次为什么呢 ?
A.难道查询比表扫描还要慢,答案是对的,数据量小的时候,聚集索引的优势体现不出来。
Q 为什么是2次逻辑读取
A 现在查询的时候如聚集索引图,先查询索引页 ,查找到对应的键值后,扫描数据页,如果有包含索引,直接在索引页就可以提取到需要的数据。
上面说了小数据量的时候聚集索引体现不出效果,下面我们继续填充数据测试 。
填充测试数据到1000
表扫描
消息:
表'employee'。扫描计数1,逻辑读取36 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
聚集索引扫描
消息:
表'employee'。扫描计数1,逻辑读取2 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
这个时候聚集索引的优势就先显示出来了 O(∩_∩)O
下面在来讲讲transaction sql 语句 ,大家在网上看到的一些人说 In like left 不使用索引 ,我们动手来测试下看他们说的对不对 ?
删除employee表的索引
DROP INDEX employee.Idx_emp_username
打开IO信息(北京北大青鸟)
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username in ('刘10000')
消息:
表 'employee'。扫描计数 1,逻辑读取 371 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
--添加Idx_emp_username聚集索引
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SELECT * FROM employee WHERE employee.emp_username in ('刘10000');
消息:
表 'employee'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用索引后逻辑读取3次,没有使用索引是371次,IN 很好的使用了索引!
下面我们来测试下 LIKE 是否很好的使用索引
删除索引
DROP INDEX employee.Idx_emp_username
打开IO 信息
SET STATISTICS IO ON
执行查询
SELECT * FROM employee WHERE employee.emp_username like ('刘1000%')
消息:
表 'employee'。扫描计数 1,逻辑读取 371 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
添加索引
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username like ( '刘1000%');
表 'employee'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
网上很多优化的文章写到查询不要使用 in like left ,其实自己动手测试下看看查询计划就一幕了然了(北京北大青鸟)




